Generating Holistic 3D Human Motion from Speech
CVPR2023
Hongwei Yi1*, Hualin Liang2*, Yifei Liu2*, Qiong Cao3†, Yandong Wen1, Timo Bolkart1, Dacheng Tao34, Michael J. Black1†
1Max Planck Institute for Intelligent Systems, Tübingen, Germany
2South China University of Technology 3JD Explore Academy 3The University of Sydney
* denotes equal contribution, † denotes joint corresponding authors
Abstract
This work addresses the problem of generating 3D holistic body motions from human speech. Given a speech recording, we synthesize sequences of 3D body poses, hand gestures, and facial expressions that are realistic and diverse. To achieve this, we first build a high-quality dataset of 3D holistic body meshes with synchronous speech. We then define a novel speech-to-motion generation framework in which the face, body, and hands are modeled separately. The separated modeling stems from the fact that face articulation strongly correlates with human speech, while body poses and hand gestures are less correlated. Specifically, we employ an autoencoder for face motions, and a compositional vector-quantized variational autoencoder (VQ-VAE) for the body and hand motions. The compositional VQ-VAE is key to generating diverse results. Additionally, we propose a cross-conditional autoregressive model that generates body poses and hand gestures, leading to coherent and realistic motions. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. Our novel dataset and code will be released for research purposes at https://talkshow.is.tue.mpg.de.
Given an input audio, TalkSHOW can generate realistic and diverse holistic human motions.
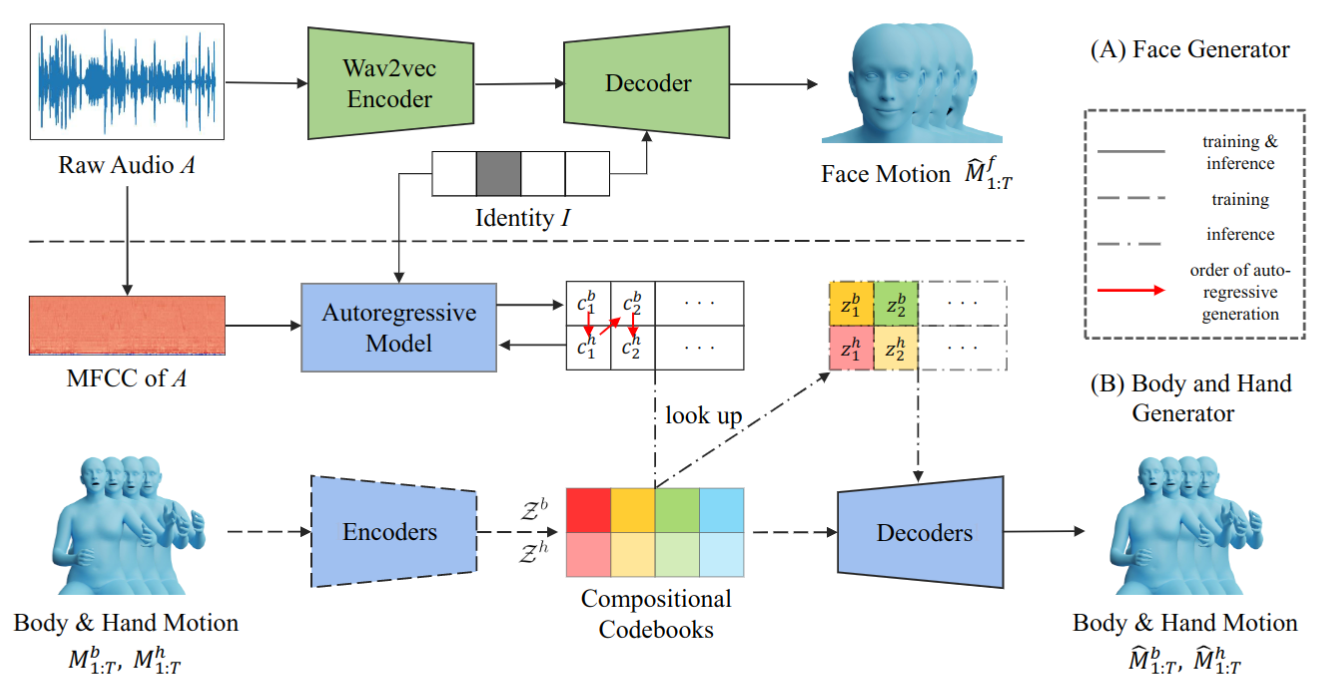
.
More examples.
TalkSHOW can generate various style holistic motions for different characters.
TalkSHOW can generalize on the audio from unseen characters.
TalkSHOW can generalize on foreign languages, e.g. French, w/o fine-tuning.
Compare Habibie et.al. with TalkSHOW .
SHOW: Synchronous Holistic Optimization in the Wild.
To train TalkSHOW, we propose SHOW to reconstruct holistic body motion from in-the-wild Youtube videos, to collect the synchronous audio and holistic body motion dataset.


Compared with SMPLify-X, PIXIE and PyMAF-X

Compared with Habibie et al. and its' Inverse Kinematic Results
Comprehensive Explanatory Video
Poster
Paper


Code and Data
The data reconstructed by SHOW is released, you can download it by logging in.
TalkSHOW code and pretrained model: TalkSHOW
SHOW code: SHOW
Acknowledgement & Disclosure
Acknowledgement. We thank Wojciech Zielonka, Justus Thies for helping us incorporate MICA into our reconstruction
method, Yao Feng, Zhen Liu, Weiyang Liu, Changxing Ding and Huaiguang Jiang for the insightful discussions, and Benjamin Pellkoferfor IT support.
This work was supported by the German Federal Ministry of Education and Research (BMBF): Tübingen AI Center, FKZ: 01IS18039B.
Disclosure. MJB has received research gift funds from Adobe, Intel, Nvidia, Meta/Facebook, and Amazon.
MJB has financial interests in Amazon, Datagen Technologies, and Meshcapade GmbH.Citation
@inproceedings{yi2023generating,
title={Generating Holistic 3D Human Motion from Speech},
author={Yi, Hongwei and Liang, Hualin and Liu, Yifei and Cao, Qiong and Wen, Yandong
and Bolkart, Timo and Tao, Dacheng and Black, Michael J},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
pages={469-480},
month={June},
year={2023}
}
Contact
For commercial licensing, please contact ps-licensing@tue.mpg.de